táxis de Portugal
Growing up in Detroit I was surrounded by car culture, whether marveling at concept vehicles in the auto show or admiring American classics during the annual Woodward Dream Cruise. To me the automobile was a piece of one's identity, and car ownership (or even access to a parent's car) was freedom. It wasn't until my senior year of high school when I collaborated in making a physics curriculum focusing on DSRC vehicle-to-vehicle communication, traffic signal preemption and "smart highways" that I came to appreciate cars as simply nodes in a vast network of people and the places we go.
I've put off pursuing my interest in this industry for too long. To start getting a feel for the problems facing these companies, I crept around online looking for interesting datasets until I found this one on Kaggle which contains a year's worth of taxi trajectories from the city of Porto, Portugal. The Kaggle challenge (which had ended before I found it) was to predict the destination of the ride from the trajectory and other fare details. I am more interested in learning about ride sharing so as a first pass I play around with the dataset and do some basic visualization below. Check out my GitHub for the code if you want to follow along. Have to start somewhere....
To start I focused on the "organically" hailed rides as these more closely resemble the use case of Lyft and Uber, as opposed to rides scheduled hours in advance or those originating from a taxi stand. After discarding some entries with bad data or genuine outliers (e.g. trips of several hundred kilometers or speeds exceeding 200 kmph), I had about 5 x 10^5 rides. Each trip contains a list of coordinates representing the car's location at 15-second intervals. This dataset was cumbersome enough for my ThinkPad with 4GB of RAM that I opted to read it into HDF5 format as PyTables which interfaces nicely with Pandas and allows one to do out-of-core manipulation on the data. I may do some traffic simulations on these data so it was worth the up-front investment to store it in a highly queryable representation (I'm interested in learning other alternatives--I used HDF5 often to handle trading data).
Being unfamiliar with this type of dataset, I was pleasantly surprised to see recognizable output when I generated a 2D histogram of every point visited. I used logarithmic binning in hopes of finding whatever roads were traveled, not placing too much emphasis on whether it was a major thoroughfare. This picture is just plain cool. There is something exciting about turning an unwieldy CSV file into something understandable.
A 2D histogram of the organically hailed trips throughout the Porto metropolitan area.
Right away we notice a few clusters of high traffic areas. To quantify this observation, a simple technique is to apply some K-means clustering to the ~0.5mm trip destinations and notice how much of the total distribution is explained by adding additional "hubs". The intuition is that in an extreme case where every trip were destined to one of a few destinations (e.g. city center, airport, financial district, industrial area, etc.), we could come up with K destinations that tell the whole story. The real data will never be explained completely by so few points but it is instructive to notice how close you can get.

Notice that as we increase the number of clusters K, the total squared distance between rides and their nearest cluster naturally decreases. At some point, around K=5 or 6, it is clear that adding more clusters offers little additional explanatory valuable.
It is clear from the above that by focusing on just 5 or 6 locations, we can go a long way toward understanding the entire distribution of destinations in Porto. I use the numpy.spatial package to overlay a K=6 Voronoi diagram on top of a heatmap of destinations. It immediately becomes clear that in addition to what appears to be the city center, there are some distinct regions including a remarkably concentrated area to the northwest of downtown. I find it easier to deal in terms of Euclidean coordinates instead of latitude/longitude so I performed a simple Mercator projection on the given GPS data.
A heat map of the destinations visited overlaid with a Voronoi diagram which indicates the classification boundaries for the K=6 clusters.

Gee let's think for 5 seconds about what cluster No. 2 could be: the airport? Yep!
And with just a few minutes doing a split-screen scavenger hunt on Google Maps, I can identify a few more hot spots in the other clusters:
- Region 0 has a very visible traffic circle surrounding a popular park; elsewhere a hopsital and shopping center
- Region 1 has two major train stations
- Region 3 is a parish called Pedrouços
- Region 4 is obviously downtown
- Region 5 has a port with nothing very touristy on the map
I can imagine if I were in charge of improving ridership in an unfamiliar city, doing a simple K-means clustering like this would help develop a qualitative understanding of "where do people go". One can even make a transition matrix like the one below (and monitor it over time) to get a high level sense of the flow of fares across the map.
Transition matrix. Square in (row=i, column=j) represents the percentage of rides arriving in cluster j that originate in clutser i.
This transition matrix, which is normalized so each column (each destination) sums to 1.0, shows that for any destination (i.e. no matter the column), the origin of most rides is from downtown (cluster #4). As can be expected, very few rides are both starting and ending at the airport (sounds like a boring ride!). Moreover, relatively few rides are originating at the airport at all (hence the lightness of row 2) but on a per-pixel-basis the airport still just as busy a node as anywhere else--it's just that the rest of cluster #2 is pretty dead.
Obviously another problem facing any ridesharing/taxi company is anticipating the supply and demand for rides. To this end I made an hourly, weekdaily, monthly and intra-month seasonality chart to see if we can spot any trends.
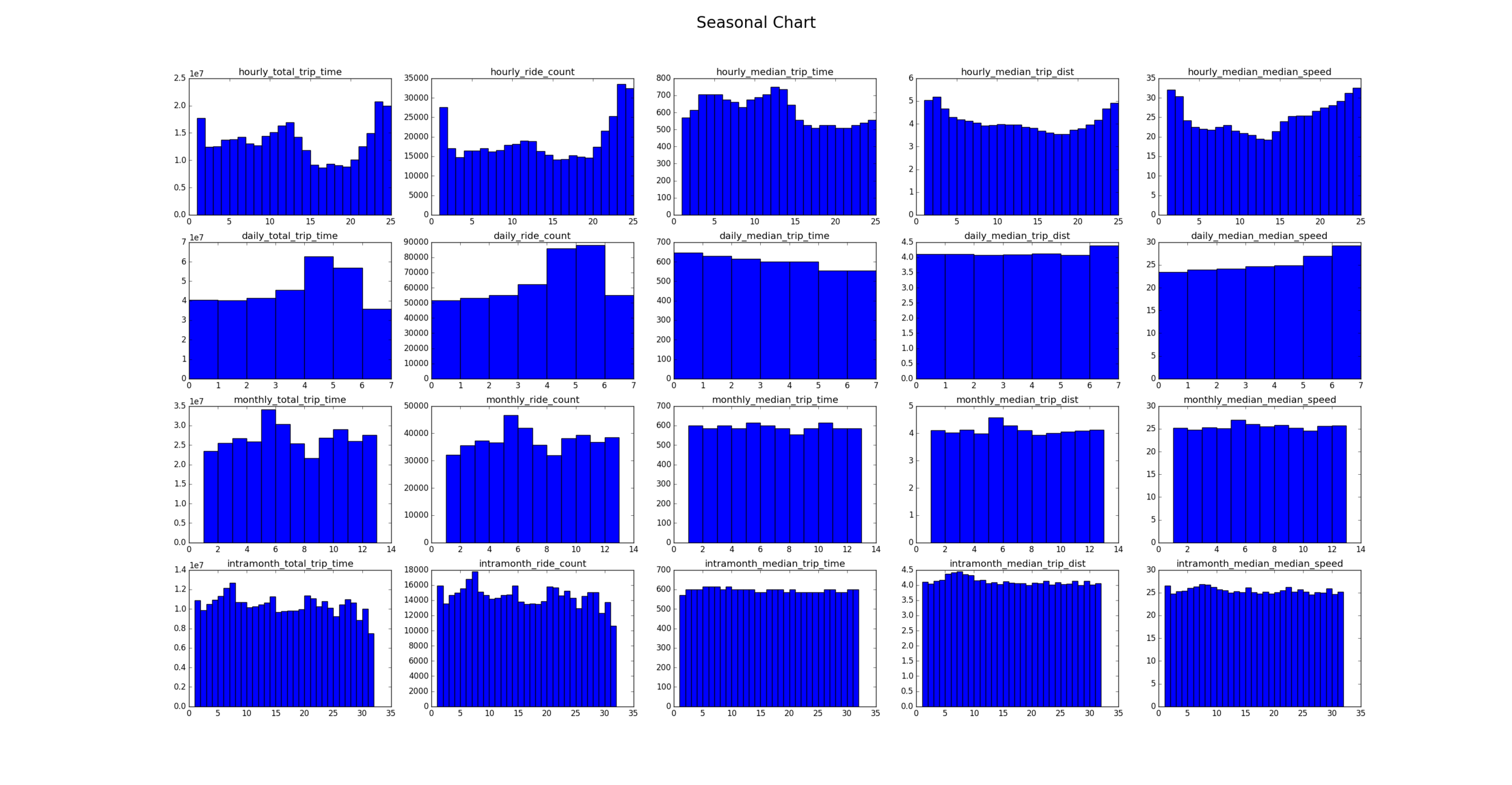
Naturally in the upper left graphs you can see a lull of total trip time during the workday, consequently the median trip time is also lower during these lower traffic times. In the second row we see that Fridays and Saturdays are the most popular days for hailing taxis from street level. In the monthly row we notice a dip in total hours driven around month=8, this ties out with the conventional wisdom that many professionals in Western Europe take off the month of August for holiday. In the fourth row, we see a spike in total trip hours by the 5th to 7th day of the month. One explanation for this might be Catholic residents participating in The First Saturdays Devotion which is related to an apparition of the Virgin Mary witnessed by a schoolgirl in Porto in 1925.
So can we make anything of all this? In my next post I'll follow up with a more thorough traffic and ridesharing simulation, but as a proof of concept I'll use the airport as an example. Just visually we can see that the airport is a popular yet far away destination, and one that people are probably more content than usual to wait a few extra minutes getting to if it means saving money. A proper ridesharing algorithm would dynamically consider whether to add new passengers to existing rides by considering the total change in miles traveled among other factors. As a starting point, I just combined the trips of any two passengers going to the airport within 10 minutes of each other and starting up to .5km apart as the crow flies. Instead of using the GoogleMaps API to recalculate the route, I used a back-of-the-envelope approximation from this graph below which suggests that the trip distance of a taxi ride is ~1.3 times longer than the distance the crow flies.

A histogram-scatter of the as-the-crow-flies distance to that traveled by the taxi.
The graph above speaks to the tight relationship between arc-length and Haversine distance for most rides. This basically allows us to use the computationally simpler Haversine or Euclidean distance when considering the increased mileage of adding passenger B to passenger A's ride.
Just this naive one-off rideshare algorithm reduced total miles driven to the airport by ~5% while still delivering ~12,000 passengers to their destination with an average extra time spent driving out of the way for those effected of only 6 minutes. In my next post I will implement a more thorough ride sharing algorithm and hopefully see some synergies from considering the full gamut of multiple destinations (not just the airport) and points along the way (on the way to the airport).
In this post I have scratched the surface of this interesting Porto taxi data set, confirming some intuitions and finding some low hanging opportunities for improving efficiency. It has been a good start to understanding some of the problems these companies face.